Examples
Notes
Parameters
Note: For the full list of parameters available for this method, see Global parameters for methods. The following table shows parameters most relevant to or specific to this method.Examples
The following example shows extracting two columns using the Fixed Table method.- In order to omit column headings, the config specifies
"type": "number"and"isRequired": truefor the columncol4_rank_last_month. You can also use"startOnRow":1to omit headings. - To improve performance, the config specifies a Stop parameter.
JSON
The following image shows the example document used with this example config:

Output
JSON
Example: Merged cells
The following example shows using the Stop parameter to improve output for merged cells: ConfigJSON
The following image shows the example document used with this example config:

Output
Without the Stop parameter, Sensible leaves “merged” cells empty:
 With the Stop parmeter, Sensible populates “merged” cells:
With the Stop parmeter, Sensible populates “merged” cells:
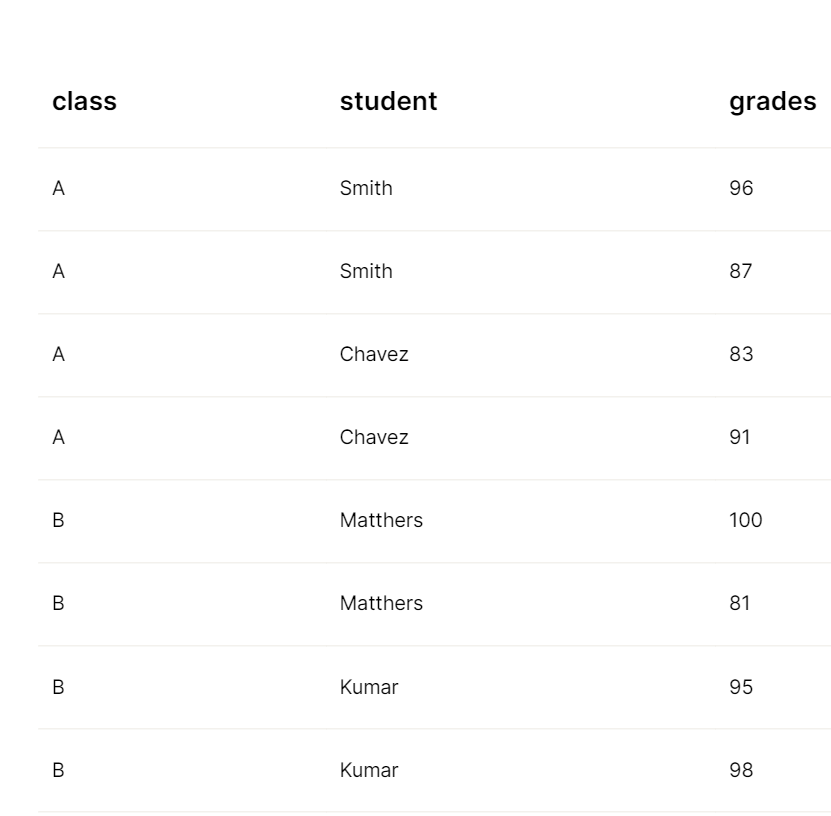 The following JSON shows the “populated” output:
The following JSON shows the “populated” output:
JSON
Example: Troubleshoot table OCR
The following table shows troubleshooting OCR in a table. ConfigJSON
The following image shows the example document used with this example config:

Output
JSON